Rodolfo Antunes

Using Random Forest to predict Song Popularity on Spotify
Project description: Can we use a publicly available dataset on Spotify songs to create machine learning models that can accurately predict song popularity on Spotify? In other words, can we predict what people like listening to the most?
1. Import and Clean data
We have two datasets, one containing information on artists and the other on songs. We should first filter noisy data to then merge our two datasets using a unique identifier (In this case, id_artists). Noisy data includes information on songs that might be composed of only speech (like podcasts), no popularity (this could make our analysis unbalanced) and 0 time signature (this could be a typo or experimental music).
df = df[df['speechiness']<0.66]
df = df[df['popularity']>0]
df = df[df['time_signature']>0]
Next we should merge our two datasets and begin our analysis.
df2 = df.merge(df1, on = 'id_artists')
2. EDA (exploratory data analysis)
By taking a first look at our data we can definitely see some trends:
• Most of our songs were released after the 1980s.
• The majority of songs were composed in the major scale, in 4/4 time signature, in the Keys of C, F#, G#, D and recorded in studio.
• Moreover, most songs are also not explicit and have a duration between 2 and 6 minutes.
• As for Artists, the followers feature was highly skewed (with a minimum of 1 follower, maximum of 78 million and averaging 1.1 million).
• Artist Popularity was also skewed (with a minimum of 1, maximum of 100 and averaging 51).
• However, the most popular artists (Justin Bieber, Taylor Swift, Bad Bunny…) were not necessarily the artists with the most followers on Spotify (Ed Sheeran, Ariana Grande, Drake…).
Then, we’ll split songs based on their popularity. Songs under the average popularity will be considered not popular, while songs over the average point will be considered popular and will be our target variable. By taking a first look at our features when comparing the two categories, “artist_popularity” and “release_year” seem to be the most important features.
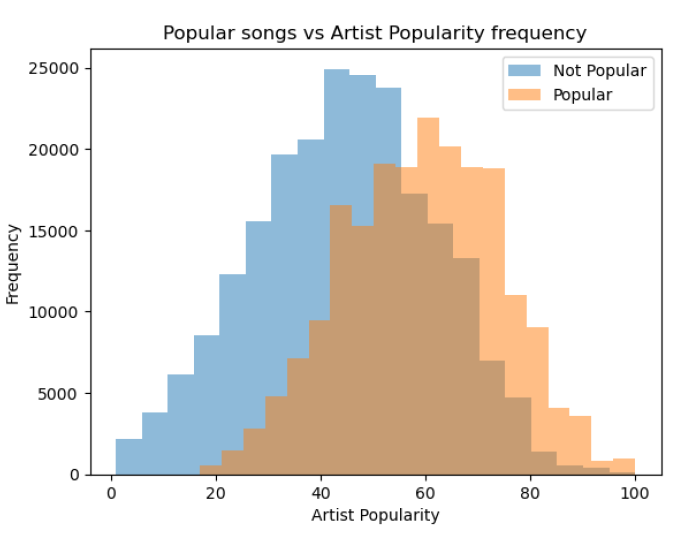
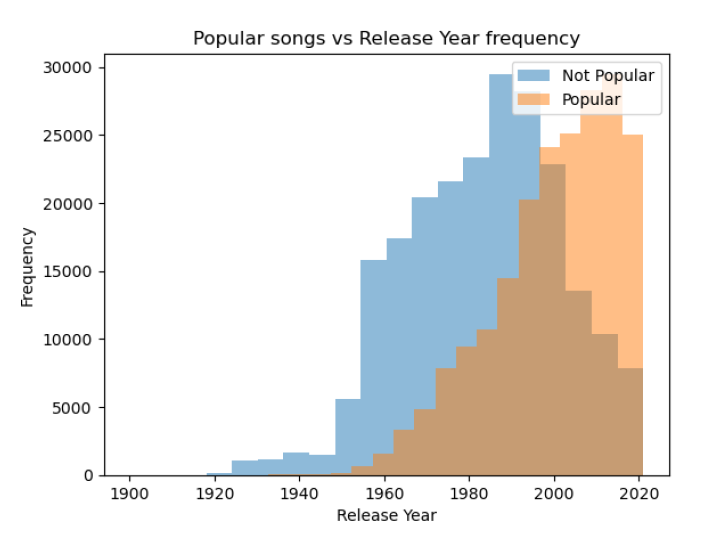
3. Feature Engineering
We can then create a new feature to help our machine learning models predict our results with higher accuracy. We should create a new feature to verify if artists that release more songs tend to be more popular.
# Set a dataframe with the song counts per artist
counts_songs = df2['artist'].value_counts()
# Merge both datasets on artist
df2 = pd.merge(df2, counts_songs, left_on='artist', right_index=True)
# drop duplicated column
df2 = df2.drop(columns='artist_x')
# rename count column
df2 = df2.rename(columns={'artist_y': 'NOS_artist'})
4. Create Machine Learning Models
Since our target variable is binary it makes sense to start with Logistic Regression and follow up with Decision Tree Classifier. After seeing that Descision Tree Classifier had very positive results, it makes sense to try a Random Forest model.
After hyperparameter optimization we can compare the results we got with each model by measuring accuracy, recall, precision, F1 score and plotting the ROC/AUC.
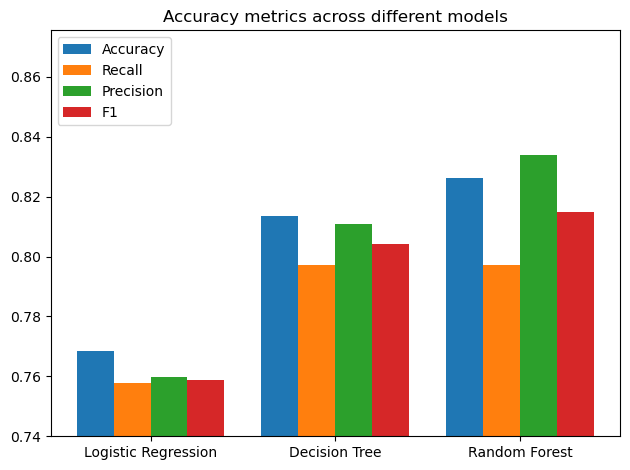
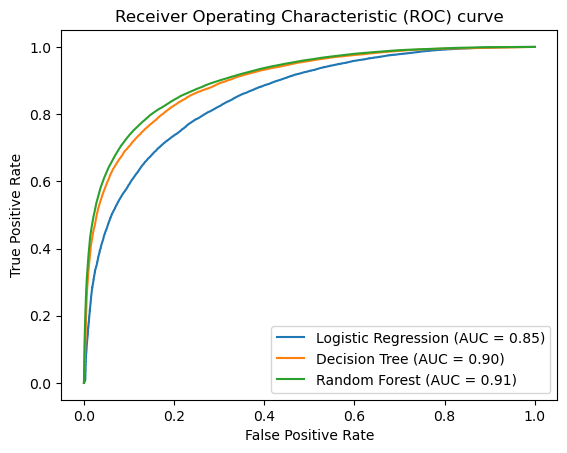
5. Conclusion and actionable steps
• Popular songs tend to have higher energy, be less explicit and last between 2 to 6 minutes.
• Not necessarily the artist with most followers on Spotify scores higher on Artist Popularity.
• Songs released after the 2000s have a much higher tendency to become popular.
• Artist popularity matters, people view songs as popular if they were made by artists they already know.
• With an accuracy of about 83% our Random Forest was our best performing model.
To summarize, we have identified several crucial insights and developed models that are reasonably effective in predicting a song’s level of popularity on Spotify. We also tested the effectiveness of our models, making sure that they are valid and could provide insights to future projects; furthermore, creating value to artists, companies, and the music industry in general.
For more details see Project Files